The Inherent Difficulties of Scaling Microservices
The architecture of distributed applications presents severe operational friction when scaling is attempted. In a monolithic application, scaling simply involves duplicating the entire application stack across larger servers. However, splitting an application into independent microservices introduces a complex web of distributed computing challenges where every operational dimension becomes harder to manage manually:
Scheduling
Workload placement is rendered exceptionally difficult because manual intervention cannot keep pace with rapidly shifting system demands. When a new service instance needs to be deployed, a node must be selected based on dozens of real-time variables, such as current CPU utilization, available memory overhead, disk I/O constraints, and existing network traffic patterns across the cluster. Without automation, nodes quickly become unevenly loaded, causing cascading performance bottlenecks.
Affinity and Anti-affinity
Complex constraints regarding container placement must be continuously evaluated. Affinity rules are required to ensure that co-dependent microservices (such as a web frontend and its low-latency in-memory cache) are placed on the same physical host or rack to minimize network latency. Conversely, anti-affinity rules must be strictly enforced to ensure that duplicate instances of a critical service are isolated across different physical machines or availability zones. This ensures that a single hardware failure cannot take down an entire operational tier.
Health Monitoring
Continuous health checking must be systematically enforced across hundreds of running containers. In a microservices environment, a process can remain active while the application inside it is completely frozen, deadlocked, or unable to connect to its database. Traditional ping-based infrastructure checks are insufficient; instead, deep, multi-tiered application-level vitality tracking (such as liveness and readiness state checks) must be executed constantly to catch silent failures.
Failover
When instances inevitably crash or hardware degrades, manual recovery is impossible at scale. Failover mechanisms must detect a dead container, spin up an exact replica on an alternate healthy node, re-bind persistent storage, and notify the rest of the network of the change—all within seconds to prevent data loss or service degradation for end users.
Scaling
As business workloads fluctuate throughout the day, application capacity must adapt dynamically. Manually provisioning resources during traffic spikes leads to slow response times, while over-provisioning results in massive financial waste. Scaling requires automated, granular, and rapid adjustments to both individual container replicas and the underlying physical hardware pool without introducing a single second of application downtime.
Networking
In a microservice ecosystem, static IP allocation completely breaks down. Containers are ephemeral; they are constantly created, destroyed, and moved across different servers. Because of this high-churn environment, traditional firewall rules and static routing tables cannot adapt quickly enough, making secure, isolated, and low-latency network communication highly complex to maintain.
Service Discovery
Because network paths are constantly shifting, an automated system is required so microservices can locate and communicate with one another dynamically. For example, a checkout service cannot rely on a hardcoded IP address to send requests to a payment service. It requires a resilient, internal lookup mechanism (like a dynamic cluster-wide DNS) that registers new endpoints the moment they become healthy and strips them out the instant they fail.
Coordinated App Upgrades
Rolling out updates across a distributed system is incredibly risky. Upgrades must be systematically orchestrated using strategies like rolling updates or blue-green deployments to ensure that zero downtime occurs. If a core service is updated, the system must gradually shift traffic to the new version while continuously monitoring for errors, maintaining the capability to perform an instant, automated rollback if a regression is detected.
The Structural Architecture of Kubernetes
To resolve these microservice complications, Kubernetes is widely implemented across the cloud-native community as a foundational open-source project. However, Kubernetes is highly complex. Within this ecosystem, communications are initiated by users who interact with a centralized API server to declare and apply a specific desired state.
Once this configuration is ingested, the desired state is actively enforced on the underlying agent nodes by a centralized control plane. Simultaneously, intra-cluster communication between distinct containers, as well as external communication routed directly from the internet, is fully supported by the agent nodes.
To maintain this sophisticated orchestration layer, a standard Kubernetes environment is split cleanly into two primary operational sections: the Control Plane and the Agent Nodes.
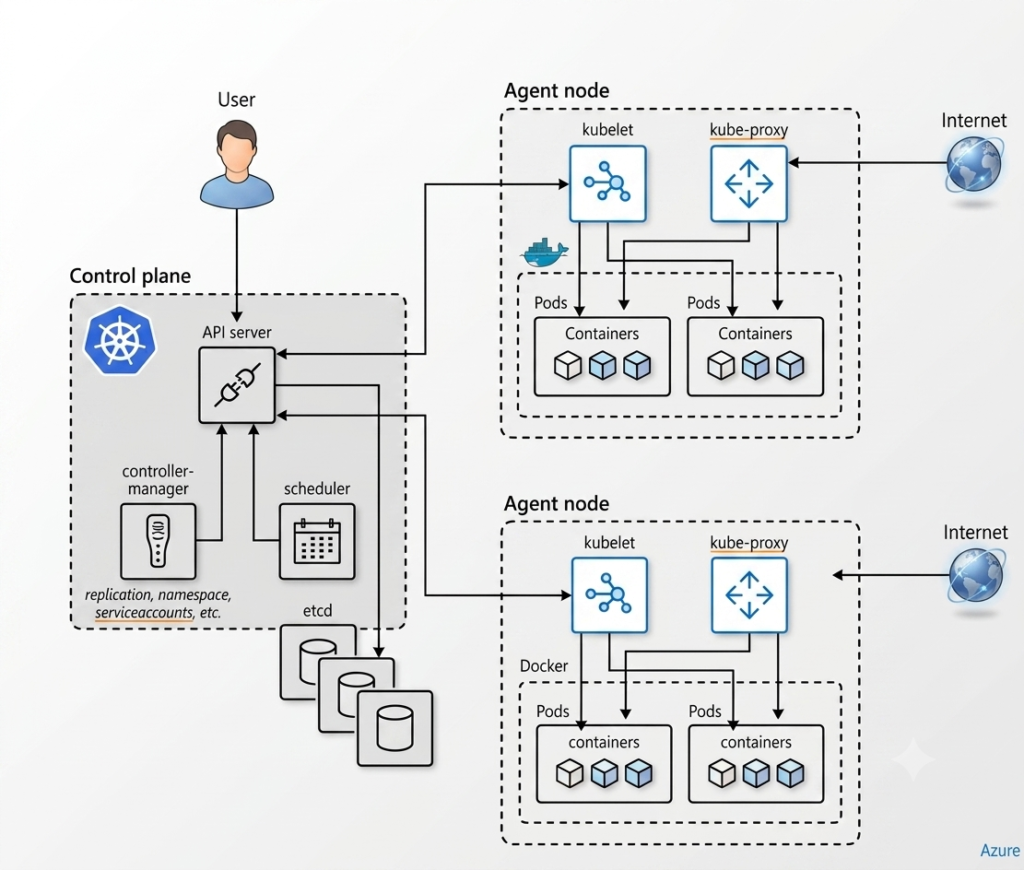
The Control Plane (Master Node)
The Control Plane, frequently designated as the master node, acts as the core administrative brain of the cluster where everything is interconnected and processed. In managed cloud environments, this control plane infrastructure is fully maintained behind the scenes by cloud providers such as Azure. It is structurally comprised of the following subsystems:
API Server
This component serves as the primary point of communication for external users, management tools, and worker nodes alike. The entire internal cluster state is exposed strictly through this API interface.
Scheduler
An algorithm-based software component that is utilized to watch for newly created PODs that lack an assigned node. A worker node is calculated and selected for them based on CPU availability, taking an optimized best guess to put the containers into active production.
Controller Manager
This sub-system is utilized to manage vital background controller processes. It is granted programmatic access to infrastructure provider resources (such as Azure disks or network load balancers) on behalf of users whenever modifications are required.
etcd
A consistent, highly-available distributed key-value store wherein all configurations, secrets, mappings, and cluster data are safely stored.
The Agent Nodes (Worker Nodes)
In contrast to the managed master layer, the Agent Nodes represent the tangible worker machines where workload replication is physically executed. This is the explicit layer where access is granted to operators and where deployment engineering is performed. Every agent node contains these vital components:
Kubelet
A dedicated local agent or client of the API server that is executed on every single node across the cluster. Everything that happens locally on the machine is continuously monitored and managed by this agent.
Kube-Proxy
A specialized network proxy running on each node that implements core Kubernetes service concepts. The network pathways between different independent agent nodes are entirely handled by this layer.
Container Runtime
+-------------------+
| End User |
+---------+---------+
| (kubectl / API Requests)
v
+-------------------------------------------+-----------------------------------------------+
| CONTROL PLANE (Master Node / Infrastructure Brain) |
| |
| +--------------------+ +-------------------+ +------------------------+ |
| | Scheduler +-------->| API Server |<--------+ Controller Manager | |
| +--------------------+ +---------+---------+ +------------------------+ |
| | |
| v |
| +---------+---------+ |
| | etcd | |
| | (Key-Value Store) | |
| +-------------------+ |
+-------------------------------------------+-----------------------------------------------+
|
+--------------------------+------------------------------+
| |
v v
+----------------+-----------------+ +-----------------+----------------+
| AGENT NODE (Worker Node Floor) | | AGENT NODE (Worker Node Floor) |
| | | |
| +----------------------------+ | | +----------------------------+ |
| | Kubelet | | | | Kubelet | |
| +--------------+-------------+ | | +--------------+-------------+ |
| | | | | |
| v | | v |
| +--------------+-------------+ | | +--------------+-------------+ |
| | Container Runtime | | | | Container Runtime | |
| | (Docker / containerd) | | | | (Docker / containerd) | |
| +--------------+-------------+ | | +--------------+-------------+ |
| | | | | |
| v | | v |
| +--------------+-------------+ | | +--------------+-------------+ |
| | Replicated Pod Containers | | | | Replicated Pod Containers | |
| +----------------------------+ | | +----------------------------+ |
| | | |
| +----------------------------+ | | +----------------------------+ |
| | Kube-Proxy |<=========================>| Kube-Proxy |<===== Public Internet
| +----------------------------+ | | +----------------------------+ |
+----------------------------------+ +----------------------------------+
The actual underlying processing engine responsible for running isolated containers. Depending on the architecture, a choice of runtime platforms—specifically Docker or containerd—can be utilized by the cluster.
The point about scheduling becoming exponentially harder in a microservices environment is often underestimated, especially when resource usage changes constantly across a cluster. Kubernetes helps automate placement decisions, but I think observability is just as important—without clear metrics and monitoring, it’s difficult to know whether the orchestration layer isBlog Comment Creation actually improving workload distribution and performance.